
ұҫОДКЗ·ЦІјКҪУ–ҫҡЙсҪӣҫWҪjДЈРНИэЖӘПөБРОДХВөДөЪТ»ЖӘЎЈ
ФЪөЪТ»ЖӘОДХВЈ¬ОТӮғКЧПИБЛҪвТ»ПВИзәОК№УГGPU·ЦІјКҪУӢЛгҒнп@ЦшМбёЯЙо¶ИҢWБ•ДЈРНөДУ–ҫҡЛЩ¶ИЈ¬ТФј°•юУ‘Х“ЖдЦРГжЕRөДТ»Р©Мф‘рәН®”З°өДСРҫҝ·ҪПтЎЈОТӮғЯҖ•юУ‘Х“ФЪәО·NҲцҫ°ПВЯmәПЈЁ»тІ»ЯmәПЈ©ІЙУГ·ЦІјКҪЛг·ЁҒнУ–ҫҡЙсҪӣҫWҪjДЈРНЎЈ
өЪ¶юЖӘОДХВЈ¬ОТӮғ•юҸДApache SparkөДҫWҪjДЈРНУ–ҫҡ№ӨҫЯDeeplearning4jИлКЦЈ¬ҒнУ‘Х“ЖдҢҚ¬Fјҡ№қЈ¬ТФј°МṩһӮҖ¶ЛөҪ¶ЛУ–ҫҡөДҢҚлH°ёАэЎЈ
ЧоәуЈ¬ОТӮғЙоИлМҪУ‘Deeplearning4jөДSparkҢҚ¬FЈ¬ІўЗТУ‘Х“Т»Р©ФЪЧоҙу»ҜУ–ҫҡРФДЬөДЯ^іМЦРЈ¬ЛщУцөҪөДРФДЬәНјЬҳӢФOУӢЙПөДМф‘рҶ–о}ЎЈОТӮғТІ•юУ‘Х“SparkИзәОЕcDeeplearning4jЛщК№УГөДұҫөШёЯРФДЬУӢЛгәҜ”өҺмҪ»»Ҙ…fЧчЎЈ
ёЕКц ФЪҙу”ө“юјҜЙПУ–ҫҡөД¬FҙъЙсҪӣҫWҪjДЈРНФЪФSФS¶а¶аоIУт¶јИЎөГБЛп@ЦшөДР§№ыЈ¬ҸДХZТфәНҲDПсЧR„eөҪЧФИ»ХZСФМҺАнЈ¬ФЩөҪ№ӨҳIҪзөД‘ӘУГЈ¬ұИИзЖЫФpҷzңyәННЖЛ]ПөҪyЎЈө«КЗЯ@Р©ЙсҪӣҫWҪjөДУ–ҫҡЯ^іМ·ЗіЈәД•rЎЈұM№ЬҪьР©ДкGPUөДУІјюјјРgЎўҫWҪjДЈРНҪYҳӢәНУ–ҫҡ·Ҫ·ЁҫщИЎөГБЛәЬҙуөДН»ЖЖЈ¬ө«КЗҶОҷCУ–ҫҡәД•rЯ^ҫГөДКВҢҚИФҹo·Ё»ШұЬЎЈәГФЪОТӮғІўІ»ҫЦПЮУЪҶОҷCУ–ҫҡЈәИЛӮғН¶ИлБЛҙуБҝөД№ӨЧчәНСРҫҝҒнМбЙэ·ЦІјКҪУ–ҫҡЙсҪӣҫWҪjДЈРНөДР§ВКЎЈ
ОТӮғКЧПИҪйҪBғЙ·NІўРР»Ҝ/·ЦІјКҪУ–ҫҡөД·Ҫ·ЁЎЈ
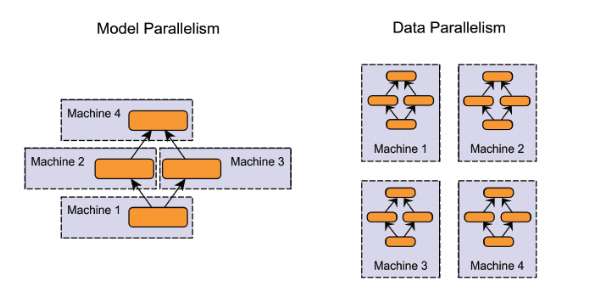
ФЪДЈРНІўРР»ҜЈЁ model parallelism Ј©·Ҫ·ЁАпЈ¬·ЦІјКҪПөҪyЦРөДІ»Н¬ҷCЖчШ“ШҹҶОӮҖҫWҪjДЈРНөДІ»Н¬Іҝ·Ц ЎӘЎӘ АэИзЈ¬ЙсҪӣҫWҪjДЈРНөДІ»Н¬ҫWҪjҢУұ»·ЦЕдөҪІ»Н¬өДҷCЖчЎЈ
ФЪ”ө“юІўРР»ҜЈЁ data parallelism Ј©·Ҫ·ЁАпЈ¬І»Н¬өДҷCЖчУРН¬Т»ӮҖДЈРНөД¶аӮҖёұұҫЈ¬ГҝӮҖҷCЖч·ЦЕдөҪ”ө“юөДТ»Іҝ·ЦЈ¬И»әуҢўЛщУРҷCЖчөДУӢЛгҪY№ы°ҙХХДі·N·ҪКҪәПІўЎЈ
®”И»Ј¬Я@Р©·Ҫ·ЁІўІ»КЗНкИ«»ҘівөДЎЈјЩФOУРТ»ӮҖ¶аGPUјҜИәПөҪyЎЈОТӮғҝЙТФФЪН¬Т»Е_ҷCЖчЙПІЙУГДЈРНІўРР»ҜЈЁФЪGPUЦ®йgЗР·ЦДЈРНЈ©Ј¬ФЪҷCЖчЦ®йgІЙУГ”ө“юІўРР»ҜЎЈ
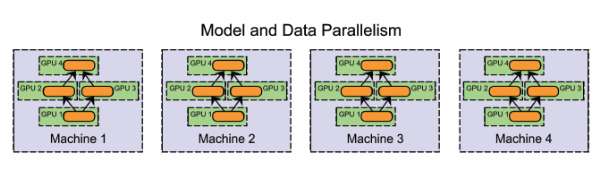
ұM№ЬФЪҢҚлH‘ӘУГЦРДЈРНІўРР»ҜөДР§№ыЯҖІ»еeЈ¬”ө“юІўРР»Ҝ…sКЗ¶а”ө·ЦІјКҪПөҪyөДКЧЯxЈ¬әуХЯН¶ИлБЛҙуБҝөДСРҫҝЎЈТ»·ҪГжЈ¬”ө“юІўРР»ҜФЪҢҚ¬Fлy¶ИЎўИЭеeВКәНјҜИәАыУГВК·ҪГж¶јғһУЪДЈРНІўРР»ҜЎЈ·ЦІјКҪПөҪyұіҫ°ПВөДДЈРНІўРР»ҜНҰУРТвЛјЈ¬УРІ»ЙЩғһ„ЭЈЁАэИз”UХ№РФЈ©Ј¬ө«ФЪұҫОДЦРОТӮғЦчТӘУ‘Х“”ө“юІўРР»ҜЎЈ
”ө“юІўРР»Ҝ ”ө“юІўРР»ҜКҪөД·ЦІјКҪУ–ҫҡФЪГҝӮҖ№ӨЧч№қьcЙП¶јҙжғҰТ»ӮҖДЈРНөДӮд·ЭЈ¬ФЪёчЕ_ҷCЖчЙПМҺАн”ө“юјҜөДІ»Н¬Іҝ·ЦЎЈ”ө“юІўРР»ҜКҪУ–ҫҡ·Ҫ·ЁРиТӘҪMәПёчӮҖ№ӨЧч№қьcөДҪY№ыЈ¬ІўЗТФЪ№қьcЦ®йgН¬ІҪДЈРН…ў”өЎЈОД«IЦРУ‘Х“БЛёч·N·Ҫ·ЁЈ¬ёч·N·Ҫ·ЁЦ®йgөДЦчТӘ…^„eФЪУЪЈә
Ўс …ў”өЖҪҫщ·Ё vs. ёьРВКҪ·Ҫ·Ё Ўс Н¬ІҪ·Ҫ·Ё vs. ®җІҪ·Ҫ·Ё Ўс ЦРРД»ҜН¬ІҪ vs. ·ЦІјКҪН¬ІҪ Ўс ДҝЗ°Deeplearning4jҢҚ¬FөД·ҪКҪКЗН¬ІҪөД…ў”өЖҪҫщ·ЁЎЈ
…ў”өЖҪҫщ …ў”өЖҪҫщКЗЧоәҶҶОөДТ»·N”ө“юІўРР»ҜЎЈИфІЙУГ…ў”өЖҪҫщ·ЁЈ¬У–ҫҡөДЯ^іМИзПВЛщКҫЈә
1.»щУЪДЈРНөДЕдЦГлSҷCіхКј»ҜҫWҪjДЈРН…ў”ө 2.Ңў®”З°Я@ҪM…ў”ө·Ц°lөҪёчӮҖ№ӨЧч№қьc 3.ФЪГҝӮҖ№ӨЧч№қьcЈ¬УГ”ө“юјҜөДТ»Іҝ·Ц”ө“юЯMРРУ–ҫҡ 4.ҢўёчӮҖ№ӨЧч№қьcөД…ў”өөДҫщЦөЧчһйИ«ҫЦ…ў”өЦө 5.ИфЯҖУРУ–ҫҡ”ө“юӣ]УР…ўЕcУ–ҫҡЈ¬„tА^АmҸДөЪ¶юІҪй_Кј
ЙПКцөЪ¶юІҪөҪөЪЛДІҪөДЯ^іМИзПВҲDЛщКҫЎЈФЪҲDЦРЈ¬WұнКҫЙсҪӣҫWҪjДЈРНөД…ў”өЈЁҷаЦШЦөәНЖ«ЦГЦөЈ©ЎЈПВҳЛұнКҫ…ў”өөДёьРВ°жұҫЈ¬РиТӘФЪёчӮҖ№ӨЧч№қьcјУТФ…^·ЦЎЈ
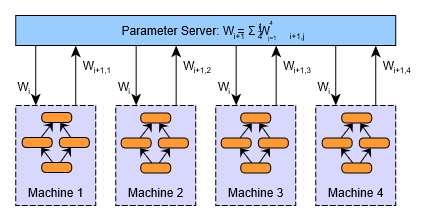
КВҢҚЙПЈ¬әЬИЭТЧЧCГч…ў”өЖҪҫщ·ЁөДҪY№ыФЪ”өҢWТвБxЙПөИН¬УЪУГҶОӮҖҷCЖчЯMРРУ–ҫҡЈ»ГҝӮҖ№ӨЧч№қьcМҺАнөД”ө“юБҝКЗПаөИөДЎЈ”өҢWөДЧCГчЯ^іМИзПВЎЈ
јЩФOФ“јҜИәУРnӮҖ№ӨЧч№қьcЈ¬ГҝӮҖ№қьcМҺАнmӮҖҳУұҫЈ¬„tҝӮ№ІКЗҢҰnxmӮҖҳУұҫЗуҫщЦөЎЈИз№ыОТӮғФЪҶОЕ_ҷCЖчЙПМҺАнЛщУРnxmӮҖҳУұҫЈ¬ҢWБ•ВКФOЦГһйҰБЈ¬ҷаЦШёьРВөД·ҪіМһйЈә
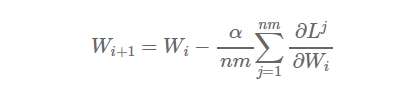
¬FФЪЈ¬јЩФOОТӮғ°СҳУұҫ·ЦЕдөҪnӮҖ№ӨЧч№қьcЈ¬ГҝӮҖ№қьcФЪmӮҖҳУұҫЙПЯMРРҢWБ•ЈЁ№қьc1МҺАнҳУұҫ1Ј¬ЎӯЎӯЈ¬mЈ¬№қьc2МҺАнҳУұҫm+1Ј¬ЎӯЎӯЈ¬2mЈ¬ТФҙЛоҗНЖЈ©Ј¬„tөГөҪЈә
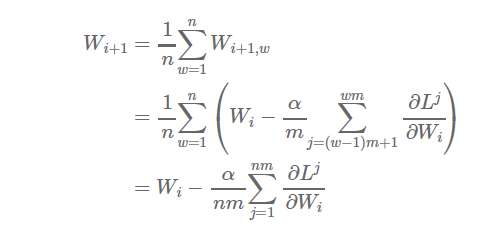
®”И»Ј¬ЙПКцҪY№ыФЪҢҚлH‘ӘУГЦРҝЙДЬІўІ»ҮАёсТ»ЦВЈЁҸДРФДЬәНКХ”ҝРФөДҪЗ¶ИҒнХfЈ¬ҢҰЛщУРminibatchЯMРРЖҪҫщәНІ»ІЙУГЦTИзmomentumәНRMSPropЦ®оҗөДupdaterөДҪЁЧh¶јЭ^һйЖ«оHЈ©Ј¬ө«КЗЛьҸДЦұУXЙПёжФVБЛОТӮғһйЙ¶…ў”өЖҪҫщ·ЁКЗТ»·NҝЙРРөДЧц·ЁЈ¬УИЖдКЗ®”…ў”өұ»оl·ұөДЗуҫщЦөЎЈ
…ў”өЖҪҫщ·ЁВ ЙПИҘ·ЗіЈәҶҶОЈ¬ө«КВҢҚЙПІўӣ]УРОТӮғҝҙЙПИҘЯ@ГҙИЭТЧЎЈ
КІГҙКЗ2016ДкЧоЦөөГҢWБ•өДҫҺіМХZСФЈҝ
Вю®Ӣ | Ў°ДгУРІЎЈ¬ИЛ№ӨЦЗДЬУРЛҺЎЈЎұөИөИЈЎЯ@КЗКІГҙЛҺЈҝ
Йо¶ИйLОДЈ¬ҙу”ө“юпLҝШДЗьcКВЈҝ
АыУГТ»ьcҷCЖчҢWБ•ҒнјУЛЩДгөДҫWХҫ
ДгЧгүтғһРгҶбЈҝіМРтҶTГҝМмЧФКЎөДК®ӮҖҶ–о}
ЖХНЁіМРтҶTИзәОПтИЛ№ӨЦЗДЬҝҝ”nЈҝ
Йо¶ИҢWБ•ёЕКцЈәҸДёРЦӘҷCөҪЙо¶ИҫWҪjЈЁЙПЈ©
ZynqЎӘLinuxТЖЦІҢWБ•№PУӣЈЁОеЈ©
21н“PPTЦШ°х°lІјЈәMarianaЎӘЎӘтvУҚЙо¶ИҢWБ•ЖҪЕ_өДЯMХ№Еc‘ӘУГ